什么是大-1分析 1,大-1分析指巨大数据进步分析。什么是数据 分析,怎么做数据 分析方法安排[ 数据 分析已经成为非常热门的职业,大数据 分析教师也成为热门不仅工资高,职场琐事也不多,但是如果你想做好。

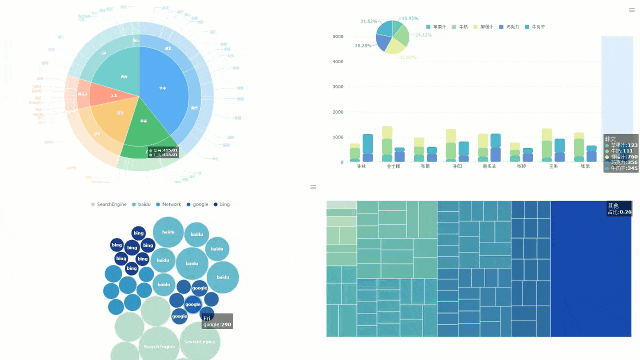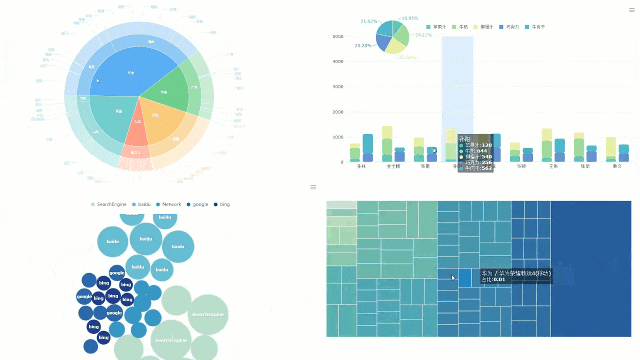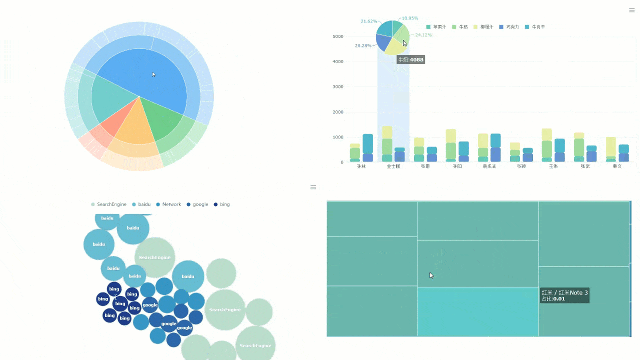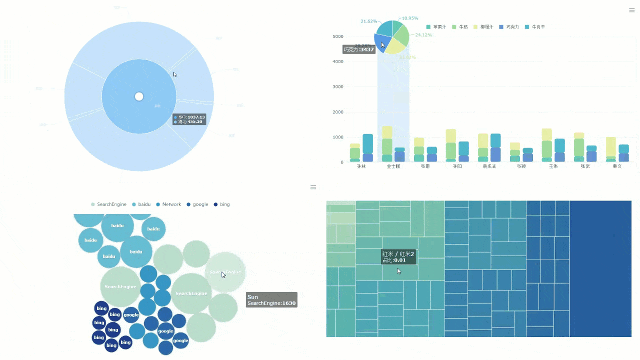
在如今这个数据的时代,数据的重要性越来越明显。但是,拥有数据不代表拥有一切。很多时候Da 数据能给出结论,却不能给出解释。只有把数据用视觉效果呈现出来,并在上面表演分析才能找出真正的答案。然而,每个问题都有不止一面。当我们面对复杂的数据问题时,核心就是去联想数据。之后就可以说我们是亲戚分析。联想分析(规则)是挖掘联想现象,从大量的数据中发现事物、特征或数据之间频繁出现的相互依赖和联系。
Stage 1:Da 数据前沿知识与hadoop介绍、Da数据前言知识介绍、课程介绍、Linux与unbuntu系统基础、hadoop单机与伪分布式模式的安装与配置。第二阶段:hadoop部署进阶。Hadoop集群模式构建,Hadoop分布式文件系统HDFS深入分析。使用HDFS提供的api操作HDFS文件。Mapreduce的概念和思想。

Mysql 数据图书馆基础知识,hive基本语法。蜂巢结构和设计原则。配置单元部署安装和案例。sqoop的安装和使用。sqoop组件被导入到配置单元中。第四阶段:Hbase理论与实战。Hbase简介。安装和配置。Hbase的数据存储。项目实战。第五阶段:Spaer配置和使用场景。Scala基础语法。Spark的介绍和发展历史,sparkstantalone模式部署。

1,factor 分析方法所谓factor 分析是指从变量组中提取公因子的统计技术。因子分析是从大量的数据中寻找内在联系,降低决策难度。因子分析的方法有10多种,如image 分析、重心法、最大似然法、最小二乘法、α-提取法、拉奥典型提取法等。2.回归分析方法回归分析方法是指统计分析方法研究一个随机变量Y对另一个(x)或一组变量的依赖性。
回归分析应用广泛。回归分析根据涉及的自变量个数可分为一元回归分析和多元回归分析。根据自变量与因变量的关系,可分为线性回归分析和非线性回归分析。3.相关性分析方法相关性分析是研究现象之间是否存在一定的依赖关系,探讨具有依赖关系的具体现象的相关方向和程度。相关性是一种不确定的关系。4.聚类分析方法聚类分析是指将物理或抽象对象集合分组到由相似对象组成的多个类中的过程。







