想搭建一个数据库,上亿的数据查询解决方案?上次插入1数据库6900万数据大概花了4~5个小时。如何处理MSSQL中的上亿数据?根据数据是否分区,莫比乌斯集群架构分为标准架构和高级架构:标准架构:每个节点拥有完全相同的数据,每个节点拥有一套完整的数据。

oracleSQL对上亿数据的主表(ZS_YJSF)进行优化,取决于它被分区了多少数据。比如一张桌子的笔数只有几百支。如果不需要关联其他大表查询数据,甚至不需要建立索引。如果是几十万级别的表,一般正确建立索引就够了。如果是一个上千万的表,不仅要正确建立索引,还要定期收集统计信息并手动维护。不建议系统自动维护,以免影响性能。如果是一亿多的表,可以考虑按照一定的条件拆分表数据,将旧数据归档,这样可以提高生成的表的利用率。

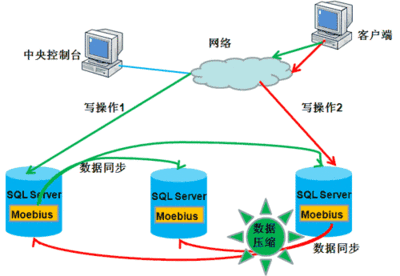
你可以看看莫比乌斯星团。莫比乌斯集群由一组数据库服务器组成,每台服务器都安装有相同的数据库。集群支持共享磁盘架构,每台机器无需共享设备即可连接,数据可以存储在自己的存储介质中。根据数据是否分区,莫比乌斯集群架构分为标准架构和高级架构:标准架构:每个节点有完全相同的数据,每个节点有一套完整的数据。

我建议你使用高级架构,因为你需要对更多的数据进行分区,从而提高查询效果。标准架构一般用于双机备份。MoebiusForSQLServer高级结构支持两种分区方式:哈希分区和线性分区。哈希分区(Hash partition):是一种根据某个字段的值将表均匀分布到若干指定分区的分区方法。优点:各分区分布的数据比较均匀,承受压力比较均匀,可以充分利用机器。
3、怎样快速向sqlserver插入上亿条数据上亿条不要有压力,按照上面的方法7秒内写完。上次插入1数据库6900万数据大概花了4~5个小时。步骤如下:1 .创建一个新表(T2);2.将旧表T的数据插入新表T2;3.删除旧表;4.重建约束和索引;其实事情已经做了,2.7亿个数据存储程序批量插入3个小时左右,就是为了探索有没有更好更方便的方式来做这件事。
4、MSSQL上亿条的数据怎么去处理?这个。上亿句话,不是一句话能搞定的。如果看起来像4000,就会数据库自行锁定。通常,使用索引。如果只有几亿条数据,就没必要单独处理。但是一定不要写SELECT*XXX这样的语句,因为这是不明智的选择。数据检索,主要有两个方面的性能设计指标。第一个是检索特定范围内的数据。例如,如果只需要几个特定的列,就没有必要检索所有的列。如果有特定的时间段,就不需要过滤所有时间范围内的数据。
数据库有上亿的商品数据需要根据商品名称进行大量的模糊查询处理(假设已经实现了商品名称的分词,即使用多个关键词进行查询)。我最初的构想是建立一个商品名称的索引表:ID、Name、ProductID三个字段按名称自动增加(分词程序把商品名称切分后,一个保留的词),ProductID、product name包含这个词的产品ID(varchar(max)字段,任何包含这个词的产品ID都有这个字段。这就是问题所在。比如一个词:黑色,有n多个产品名称可能包含黑色这个词,即使我知道这些产品id,处理起来也会很麻烦。
6、想建个 数据库,要保存上亿条商品价格信息,用哪个 数据库系统合适Oracle或者sqlserver都可以。如果只是说数据库,很多事情都可以做,比如sqlserver,oracle,mysql等,关键是如何查询和使用数据,所以实际上是一个如何选择软件的问题。这种简单的管理,不要做库存,crm等,,都太大了,大部分都不需要。遵循简单实用的管理就可以了,建议你试试华创信息管理平台,原因如下:1。用户可以自由建表,自定义数据格式,相当于数据库的网络版,针对你的情况,打造一个产品。







