比如Hadoop技术,能力弱到-2实时处理。如何使用Mahout和Hadoop处理大规模数据大规模数据规模问题?在机器学习算法中有什么实际意义?Hadoop是如何处理的?Hadoop软件处理框架1,Hadoop是一个可以分发大量数据的软件框架。
Storm比Spark和Hadoop有优势。Storm的优势在于它是一个实时、连续、分布式的计算框架。一旦运行,除非你杀了它,它总是处理正在计算或者等待计算的状态。火花和hadoop做不到。当然,它们各有各的应用场景。各有各的优势。可以一起用。我来翻一翻别人的资料,说的很清楚。Storm、Spark、Hadoop各有千秋,每个框架都有自己的最佳应用场景。

Storm是流式计算的最佳框架。Storm是用Java和Clojure写的。Storm的优势是全内存计算,所以它的定位是分布式实时计算系统。按照Storm作者的说法,Storm对于实时计算的意义类似于Hadoop对于批处理的意义。Storm的适用场景:1)Streaming数据Processing Storm可以用来处理连续流动的消息,处理后再将结果写入一个存储器。

这个SparkStreaming示例是Hadoop近实时会话持久性的一个很好的例子。SparkStreaming是ApacheSpark中最有趣的组件之一。使用SparkStreaming,您可以创建数据 pipes,使用与批处理加载数据相同的API来处理流。此外,SparkSteaming的“微批处理”方法提供了相当好的灵活性来处理某些原因导致的任务失败。

(会话化是指在单个访问者网站会话的时间范围内捕获的所有点击流活动。您可以在这里找到这个演示的代码。像这样的系统对于理解访问者的行为超级有用,不管他们是人还是机器。通过一些额外的工作,它还可以设计为窗口模式,以异步方式检测可能的欺诈。
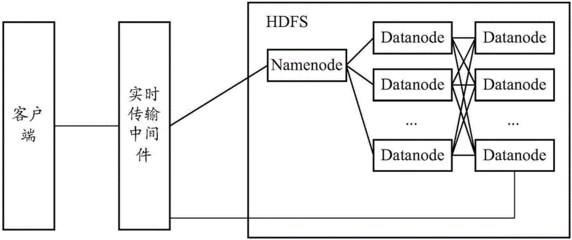
3、 hadoop集群安装完成,怎么使用现在安装完成了,你要做的就是两件事:数据在哪里?如何计算和处理数据?对于前者,可以使用hbase或者hive作为数据的存储。当然,你也可以使用hadoop你自己的分布式存储系统hdfs,但是hbase和hive可以为你提供数据 library类的结构化存储,操作起来更加方便。对于后者,可以使用hadoop自己的计算框架MapReduce,存储在哪里数据都无所谓。可以用MR离线计算数据。







